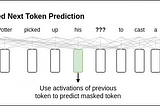
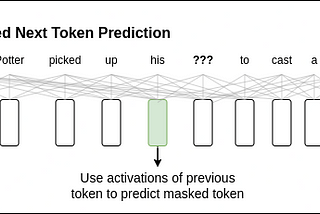
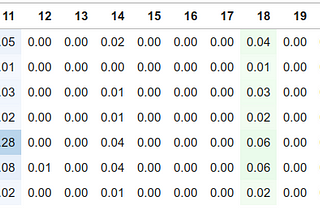
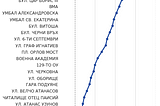
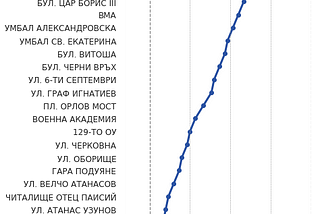
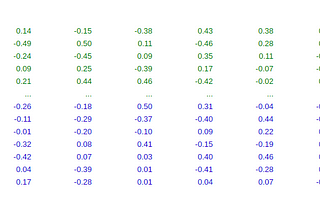
Let’s Build Bg2Vec: Apply LLM2Vec on BgGPTWith the advent of RAG and text generation solutions, it is of utmost importance to have a model which can extract meaningful…May 20, 2024May 20, 2024
K-means clustering for faster collaborative filteringThe classical collaborative filtering approach includes computing the cosine distance between all pairs of users or items. In the book…Sep 11, 2021Sep 11, 2021
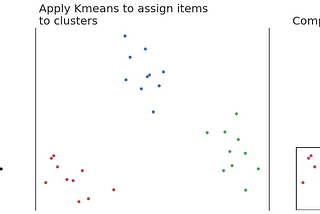
K-means Clustering for Vote AnalysisOn the 4th April 2021 we held elections in Bulgaria to choose the new parliament. This article will attempt to apply K-means clustering on…May 16, 2021May 16, 2021
72 от сутрин до вечерНапоследък чета доста Edward Tufte в опити да си увелича data viz скиловете. Идеята е, че освен красиви, графиките трябва да са и полезни…May 27, 2019May 27, 2019
Published inCommetricSemi-Frozen Embeddings for NLP Transfer LearningFinetuning only domain-specific words to reduce overfittingApr 19, 2019Apr 19, 2019
Published inCommetricDetecting Near-Duplicates in the NewsOverview and benchmark of data science methods for duplicate detectionMar 21, 20191Mar 21, 20191
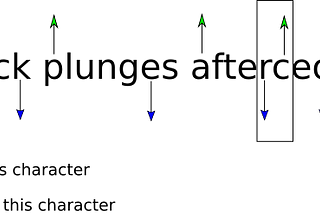
Forward & Backward Character Language Models for Conjoined Word Separation with fast.aiConjoined words are words that wrongly consist of two words. We’ll try to split them up to increase the data quality.Dec 5, 20181Dec 5, 20181
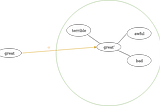
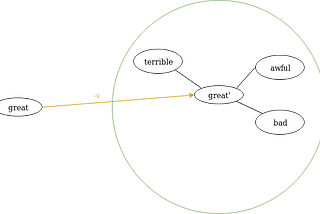
Embeddings Transformations for Sentiment Lexicon EnrichmentThere exists a vector v, such that translating a negative word n by v leads to the vicinity of the antonym of n.Sep 9, 2018Sep 9, 2018
Published inBecoming Human: Artificial Intelligence MagazineNeural Style TransferSurviving the Game Jam without artistsFeb 1, 2018Feb 1, 2018